

Estructuras de datos en R: Data Frames
Rosa Molina
Esta entrada es parte de la serie Estructuras de Datos en R. Veremos a detalle la estructura más importante en el análisis de datos, los data frames.
Seguramente ya los has usado, pero si no, no te preocupes. Aquí aprenderás todo sobre ellos. Desde su creación y acceso, hasta su manipulación y modificación. Vamos allá.
ADVERTISEMENT
Los data frames son estructuras de dos dimensiones y forma tabular. Son lo más parecido que tiene R a una hoja de cálculo.
Están conformadas por filas (sobre la horizontal) y columnas (sobre la vertical). Las columnas normalmente representan variables, mientras que las filas representan observaciones de esas variables.
Vamos a crear nuestro propio data frame y revisar las formas que tenemos para visualizarlo. Como ejemplo usaremos las películas más taquilleras del cine.
#Para crear una data frame, tenemos que definir primero las columnas#Definiremos vectores y factoresnombre <- c("Avengers: Endgame", "Avatar", "Titanic", "Star Wars: Episodio VII", "Avengers: Infinity War")distribuidor <- factor(c("Walt Disney Pictures", "20th Century Fox", "20th Century Fox", "Walt Disney Pictures", "Walt Disney Pictures"))presupuesto <- c(356000000, 237000000, 200000000, 245000000, 356000000)año <- c(2019, 2009, 1997, 2015, 2018)#Luego usamos la función data.frame()peliculas <- data.frame(nombre, distribuidor, presupuesto, año)
La función data.frame() sirve para definir data frames. Sus argumentos son los vectores o factores que serán las columnas, separados por comas.
Otra forma, tal vez más avanzada, de definir data frames es definiendo los vectores y factores dentro de la definición del data frame. De la siguiente manera:
peliculas <- data.frame(nombre = c("Avengers: Endgame", "Avatar", "Titanic", "Star Wars: Episodio VII", "Avengers: Infinity War"),distribuidor = factor(c("Walt Disney Pictures", "20th Century Fox", "20th Century Fox", "Walt Disney Pictures", "Walt Disney Pictures")),presupuesto = c(356000000, 237000000, 200000000, 245000000, 356000000),año = c(2019, 2009, 1997, 2015, 2018))
Los argumentos de la función data.frame() siguen siendo los vectores y factores que serán las columnas, separados por comas. Pero ahora los especificamos con su nombre, seguido de un "=", y luego su definición.
No importa la forma que uses, el resultado es el mismo.
peliculas
nombre distribuidor presupuesto año 1 Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 2 Avatar 20th Century Fox 2.37e+08 2009 3 Titanic 20th Century Fox 2.00e+08 1997 4 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08 2015 5 Avengers: Infinity War Walt Disney Pictures 3.56e+08 2018
Voilá, ahí está nuestro data frame. Una estructura bidimensional y tabular.
Si estamos usando RStudio, podemos visualizar nuestro data frame con la función View() (con V mayúscula, no lo olvides). Aparecerá como nueva pestaña junto al script en el que estemos trabajando.
View(peliculas)
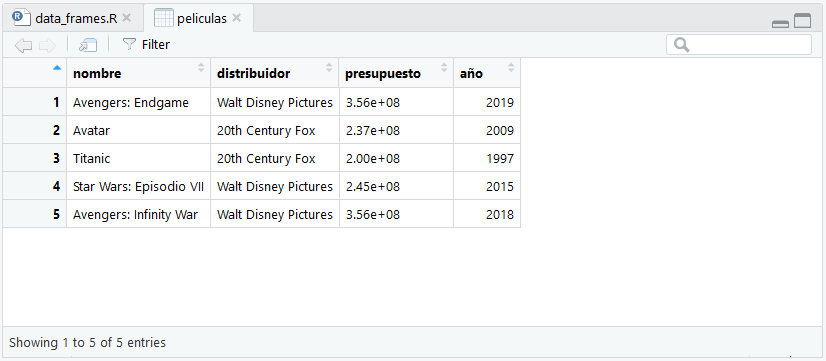
En esta imagen podemos ver la pestaña "peliculas", nuestro data frame, junto a un script (.R) llamado "data_frames". En este script escribimos y probamos el código para el blog.
Nos podemos dar cuenta que, por defecto, R numera las filas del data frame. Esto lo hace para identificar a cada observación.
Algo que podemos hacer es ponerle nombre a esta numeración que hace R. Esto se hace desde la definición del data frame con el argumento row.names:
peliculas <- data.frame(distribuidor, presupuesto, año, row.names = nombre)View(peliculas)
Dentro de nuestra función data.frame(), especificamos el argumento row.names, seguido de un "=", y luego un vector.

En lugar de la numeración, ahora vemos los valores de nuestro vector "nombre".
Anteriormente teníamos cinco observaciones (cinco películas) y cuatro variables (nombre, distribuidor, presupuesto y año). Ahora tenemos cinco observaciones con nombre y tres variables.
Importante
Sólo puedes asignar a row.names un vector con valores únicos, no puede haber valores repetidos, o R devolverá un error.
Funciones sobre data frames
Existen varias funciones que nos brindan información sobre nuestros data frames. Veremos algunos ejemplos a continuación:
#is.data.frame() nos dice si un objeto es o no es un data frameis.data.frame(peliculas)#colnames() nos devuelve los nombres de nuestras variablescolnames(peliculas)#rownames() nos devuelve los nombres de nuestras observacionesrownames(peliculas)#str() nos da información general sobre nuestro data framestr(peliculas)
[1] TRUE [1] "distribuidor" "presupuesto" "año" [1] "Avengers: Endgame" "Avatar" "Titanic" [4] "Star Wars: Episodio VII" "Avengers: Infinity War" 'data.frame': 5 obs. of 3 variables: $ distribuidor: Factor w/ 2 levels "20th Century Fox",..: 2 1 1 2 2 $ presupuesto : num 3.56e+08 2.37e+08 2.00e+08 2.45e+08 3.56e+08 $ año : num 2019 2009 1997 2015 2018
Otra función que puede resultar útil es la de transponer, es t(). Para verlo mejor, lo usaremos dentro de la función View()
View(t(peliculas))
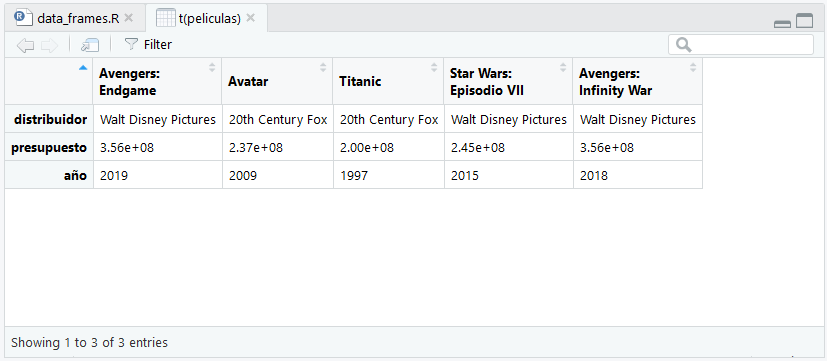
Nuestro data frame transpuesto.
Accediendo a los elementos de un data frame
Si queremos acceder a la información que contiene nuestro data frame, hay varias formas de hacerlo. Vamos a ver primero cómo acceder a ciertas columnas, luego cómo acceder a ciertas filas y luego cómo acceder a ciertas celdas (filas con columnas).
Para acceder a los elementos se pueden usar los corchetes ("[ ]") como en el caso de factores y vectores. Sin embargo, para los data frames debes usar corchetes dobles para acceder a tus columnas:
#Acceder a la primera columnapeliculas[[1]]#Acceder a la tercera columnapeliculas[[3]]
[1] Walt Disney Pictures 20th Century Fox 20th Century Fox Walt Disney Pictures [5] Walt Disney Pictures Levels: 20th Century Fox Walt Disney Pictures [1] 2019 2009 1997 2015 2018
Otra forma de obtener este mismo resultado es usando el nombre de la columna:
#Acceder a la columna llamada "distribuidor"peliculas[["distribuidor"]]#Acceder a la columna llamada "año"peliculas[["año"]]
Una tercera forma de obtener este resultado es con el signo de dinero ("$"):
#Acceder a la columna llamada "distribuidor"peliculas$distribuidor#Acceder a la columna llamada "año"peliculas$año
Una última forma es usando corchetes simples pero con una coma dentro:
#Acceder a la primera columnapeliculas[, 1]#Acceder a la tercera columnapeliculas[, 3]
Después de la coma sigue el número de columna al quieres acceder. Más abajo veremos qué es lo que puede ir antes de la coma.
Importante
Todas las opciones anteriores nos pueden devolver UNA sola columna de nuestra data frame. Además, nos la presentan en su formato de origen de vector/factor.
Si queremos acceder a una o más columnas, y verlas en formato de data frame, podemos usar las siguientes sintaxis, con corchetes simples:
#Acceder a la primera columnapeliculas[1]#Acceder a las columnas 1 y 3peliculas[c(1,3)]#Acceder a las columnas de la 1 a la 3peliculas[1:3]
distribuidor Avengers: Endgame Walt Disney Pictures Avatar 20th Century Fox Titanic 20th Century Fox Star Wars: Episodio VII Walt Disney Pictures Avengers: Infinity War Walt Disney Pictures distribuidor año Avengers: Endgame Walt Disney Pictures 2019 Avatar 20th Century Fox 2009 Titanic 20th Century Fox 1997 Star Wars: Episodio VII Walt Disney Pictures 2015 Avengers: Infinity War Walt Disney Pictures 2018 distribuidor presupuesto año Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 Avatar 20th Century Fox 2.37e+08 2009 Titanic 20th Century Fox 2.00e+08 1997 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08 2015 Avengers: Infinity War Walt Disney Pictures 3.56e+08 2018
Otra forma de obtener este resultado es con los nombres de las columnas:
#Acceder a la columna llamada "distribuidor"peliculas["distribuidor"]#Acceder a las columnas llamadas "distribuidor" y "año"peliculas[c("distribuidor", "año")]
Una última forma de acceder a más de una columna es con el sistema de corchetes con coma dentro. Recuerda que después de la coma va el número de la columna (ya casi llegamos a qué es lo que puede ir antes de la coma, paciencia).
#Acceder a las columnas 1 y 3peliculas[, c(1,3)]#Acceder a todas las columnas menos la primerapeliculas[, -1]#Acceder a todas las columnas menos la 1 y 2peliculas[, c(-1, -2)]
Para seguir adelante, veamos cómo acceder a ciertas filas (observaciones) de nuestro data frame. Esto es, por fin (!!!), escribiendo antes de la coma, dentro de los corchetes:
#Acceder a la segunda filapeliculas[2,]#Acceder a la fila 1 y a la 5peliculas[c(1,5),]#Acceder de la fila 1 a la 3peliculas[1:3,]#Acceder a todas las filas menos a la 3peliculas[-3,]#Acceder a todas las filas menos a la 2 y la 3peliculas[c(-2,-3),]
distribuidor presupuesto año Avatar 20th Century Fox 2.37e+08 2009 distribuidor presupuesto año Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 Avengers: Infinity War Walt Disney Pictures 3.56e+08 2018 distribuidor presupuesto año Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 Avatar 20th Century Fox 2.37e+08 2009 Titanic 20th Century Fox 2.00e+08 1997 distribuidor presupuesto año Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 Avatar 20th Century Fox 2.37e+08 2009 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08 2015 Avengers: Infinity War Walt Disney Pictures 3.56e+08 2018 distribuidor presupuesto año Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08 2015 Avengers: Infinity War Walt Disney Pictures 3.56e+08 2018
También podemos usar los nombres de las filas:
#Acceder a la fila de nombre "Titanic"peliculas["Titanic",]#Acceder a las filas de nombre "Avatar" y "Titanic"peliculas[c("Avatar", "Titanic"),]
distribuidor presupuesto año Titanic 20th Century Fox 2e+08 1997 distribuidor presupuesto año Avatar 20th Century Fox 2.37e+08 2009 Titanic 20th Century Fox 2e+08 1997
Además, podemos acceder a filas que cumplan cierta condición que especifiquemos dentro de los corchetes (y antes de la coma, recuerda):
#Acceder a las filas cuyo año sea mayor o igual a 2010peliculas[peliculas$año >= 2010,]#Acceder a las filas cuyo distribuidor sea "20th Century Fox"peliculas[peliculas$distribuidor == "20th Century Fox",]
distribuidor presupuesto año Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08 2015 Avengers: Infinity War Walt Disney Pictures 3.56e+08 2018 distribuidor presupuesto año Avatar 20th Century Fox 2.37e+08 2009 Titanic 20th Century Fox 2.00e+08 1997
Con todo esto que hemos aprendido, podemos seleccionar una, o varias celdas en concreto, dentro de nuestro data frame. Hagámoslo:
#Acceder a la fila 1 ("Avengers: Endgame"), columna 3 ("año")peliculas[1,3]#Acceder a las filas 1 y 5, columnas 1 y 3peliculas[c(1,5), c(1,3)]
[1] 2019 distribuidor año Avengers: Endgame Walt Disney Pictures 2019 Avengers: Infinity War Walt Disney Pictures 2018
Ahora veamos cómo funciona usar una condición para seleccionar algunas filas, mientras, al mismo tiempo, accedemos sólo a ciertas columnas:
#Acceder a las filas cuyo año sea mayor a 2015, sólo la columna 2 (presupuesto)peliculas[peliculas$año > 2015, 2]#Acceder a las filas cuyo año sea mayor a 2015, las columnas 1 y 3peliculas[peliculas$año > 2015, c(1,3)]
[1] 3.56e+08 3.56e+08 distribuidor año Avengers: Endgame Walt Disney Pictures 2019 Avengers: Infinity War Walt Disney Pictures 2018
Modificando un data frame
Si queremos eliminar una columna por completo, hay varias formas de hacerlo:
#Eliminar la columna de la variable "año" asignándole valor nulopeliculas$año <- NULL#Redefinir nuestro data frame, pero sin la columna 3 (la de año)peliculas <- peliculas[,-3]#Ambas formas resultan en lo mismopeliculas
distribuidor presupuesto Avengers: Endgame Walt Disney Pictures 3.56e+08 Avatar 20th Century Fox 2.37e+08 Titanic 20th Century Fox 2.00e+08 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08 Avengers: Infinity War Walt Disney Pictures 3.56e+08
Para agregar una nueva columna a un data frame podemos hacerlo con el signo de dinero ("$") seguido del nombre que quieras que lleve la columna:
#Si ya tienes un vector definido puedes usarlopeliculas$año <- año#Si no lo tienes, puedes definirlopeliculas$año <- c(2019, 2009, 1997, 2015, 2018)
Por otro lado, si tienes más de una nueva columna que añadir, puedes usar la función cbind(). Vamos a explorar cómo se vería nuestro data frame si le agregáramos las variables: "recaudación" y "director":
recaudacion <- c(2798000000, 2788000000, 2188000000, 2068000000, 2048000000)director <- factor(c("Russo & Russo", "Cameron", "Cameron", "Abrams", "Russo & Russo"))View(cbind(peliculas, recaudacion, director))
La función cbind() lleva como argumentos los elementos que quieres "juntar". Éstos pueden ser vectores, factores y/o data frames.

Importante
Para que cbind() funcione, los elementos que quieres añadir deben tener el mismo número de observaciones (filas). Además debes asegurarte que el orden sea el correcto.
Ahora, si lo que quieres es eliminar observaciones del data frame, puedes hacer lo siguiente:
#Redefinir el data frame con todas las observaciones menos la que no quierespeliculas <- peliculas[-5,]#O redefinirla con una condiciónpeliculas <- peliculas[!peliculas$distribuidor == "20th Century Fox",]peliculas
distribuidor presupuesto Avengers: Endgame Walt Disney Pictures 3.56e+08 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08
En nuestra condición incluimos el operador "!" que significa NO. Esto quiere decir que nos quedamos solamente con las observaciones que no cumplen la condición.
Si, por el contrario, queremos añadir más observaciones a nuestro data frame, podemos usar la función rbind().
Nuestra data frame quedó algo vacía tras eliminar tantas observaciones, vamos a llenarla de nuevo:
#Vamos a hacer de nuevo nuestro data frame completopeliculas2 <- data.frame(distribuidor, presupuesto, año, row.names=nombre)#Le quitamos las observaciones que ya están en nuestro data frame originalpeliculas2 <- peliculas2[c(-1,-4),]#Y vamos a juntarlospeliculas <- rbind(peliculas, peliculas2)View(peliculas)

En este ejemplo combinamos un data frame con otro al que le eliminamos observaciones. Sin embargo, en la práctica puede que tengas datos distribuidos en varios archivos y necesites juntarlos. Para esto sirve rbind().
Importante
Para que rbind() funcione, los data frames que quieras combinar deben tener el mismo número de columnas, y con los mismos nombres.
Para acabar con esta parte, si estás buscando la forma de editar las celdas que tienen cierto valor, lo puedes hacer de varias maneras. Vamos a ver dos formas que se relacionan con lo que hemos aprendido.
Digamos que Disney compra Fox (oops). Entonces, ahora queremos modificar todas las celdas que digan "20th Century Fox" para que ahora digan "Walt Disney Pictures". Vamos a hacerlo:
#Seleccionar, de nuestro data frame, las observaciones cuyo distribuidor sea Fox, pero sólo la columna "distribuidor", y modificar el valorpeliculas[peliculas$distribuidor == "20th Century Fox", "distribuidor"] <- "Walt Disney Pictures"#Seleccionar la columna distribuidor, sólo las observaciones cuyo distribuidor sea Fox, y modificar el valorpeliculas$distribuidor[peliculas$distribuidor == "20th Century Fox"] <- "Walt Disney Pictures"#Ambos métodos son diferentes formas de llegar al mismo resultado
distribuidor presupuesto año Avengers: Endgame Walt Disney Pictures 3.56e+08 2019 Star Wars: Episodio VII Walt Disney Pictures 2.45e+08 2015 Avatar Walt Disney Pictures 2.37e+08 2009 Titanic Walt Disney Pictures 2.00e+08 1997 Avengers: Infinity War Walt Disney Pictures 3.56e+08 2018
Data frames incluidos por defecto
Si quieres practicar tus conocimientos de R puedes hacerlo con los datos que están incluidos en R. Algunos ejemplos son: iris, mtcars y PlantGrowth. Están pre-cargados en el espacio de trabajo, así que puedes usarlos cuando quieras. Nosotros vamos a usarlos para ver unas cuantas funciones más:
#head() nos permite ver las primeras filas del data framehead(iris)#tail() nos permite ver las últimas filas del data frametail(iris)#nrow() devuelve el número de filas del data framenrow(iris)#ncol() devuelve el número de columnas del data framencol(iris)#summary() nos da un resumen estadístico de cada columna (mínmo, máximo, media, etc.)summary(iris)
Comentarios finales
Esta ha sido una entrada muy extensa. Sin embargo, creemos que es la más completa que puedes encontrar en español sobre data frames en R.
Por favor, si algo no ha quedado claro, escríbenos en los comentarios. Tenemos planeadas nuevas entradas sobre conceptos más avanzados y herramientas de manipulación más refinadas.
Eso es todo, ¡gracias por leer!
Esta publicación fue hecha usando R versión 3.6.3 (2020-02-29).
ADVERTISEMENT
← Publicación más antigua Publicación más reciente →
Acerca del autor

Rosa Molina
Rosa es nuestra bióloga experta en R. Le gusta la observación de aves y tocar el piano de vez en cuando.

Tome todas las entradas de Estructuras de Datos en R y este es un blog que realmente recomiendo para todas las personas que necesitamos recordar o aprender cosas básicas de R. La forma en que se redacta y explica cada una de las entradas es muy digerible y fácil de practicar. Agradezco a los autores de este blog por compartir este conocimiento tan importante con personas que no contamos con los recursos financieros para pagara un curso de esta calidad.